
たっきん(Twitter)です!
今回は、Seriesに値を追加や削除、また2つ以上のSeriesを結合する方法について説明していきます。
操作方法はDataFrameとほぼ同じになりますが、こちらの記事ではSeriesに特化して説明していきます。
追加、結合、削除の操作方法ですが、簡単にまとめると次の表の通りになります。
| 値の操作 | 操作方法 |
|---|---|
| 追加 | 単一値の代入方式 |
| 結合 | concat() |
| 削除 | drop() |
各操作方法について、1つずつ説明していきますので、サンプルコードを使って動作を確認していきましょう!
Pandas記事全容(目次)になります。
Pandasについて、他に困りごとある場合はこちらで答えが見つかるかもしれませんので、よかったら参考にしてみてください。


値の「追加」
値の追加するには、単一の値を直接代入します。
記述方法は、.loc[]または、インデックス[]を使った方法があります。
series.loc["ラベル"]= 単一の値
(または、series["ラベル"]= 単一の値)
サンプルコードを使って動作を確認していきましょう!
下図のように、ラベル「2020/4/9」、「2020/4/10」を1つずつ追加していくコードになります。
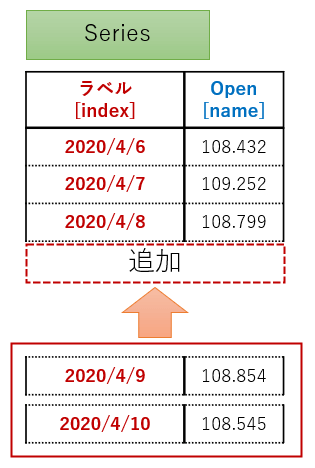
import pandas as pd
o_data = [108.432, 109.252, 108.799]
o_index = ["2020/4/6", "2020/4/7", "2020/4/8"]
# Seriesの生成
sr = pd.Series(data=o_data, index=o_index, name="open")
print(sr)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
Name: open, dtype: float64
"""
# .loc[]で値を追加
sr.loc["2020/4/9"] = 108.854
print(sr)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854 <- 追加
Name: open, dtype: float64
"""
# インデックス[]で値を追加
sr["2020/4/10"] = 108.545
print(sr)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545 <- 追加
Name: open, dtype: float64
"""Seriesの「結合」
2つ以上のSeriesを結合するにはpandas.concat()を使用します。
使用方法は結合したいSeriesをリストで引数に指定するだけです。
結合後のデータは返り値で返され、引数で指定した結合前のSeriesは変更されません。
下図のように、2つのSeriesを結合させて1つのSeriesを生成するサンプルコードで動作を確認していきましょう!
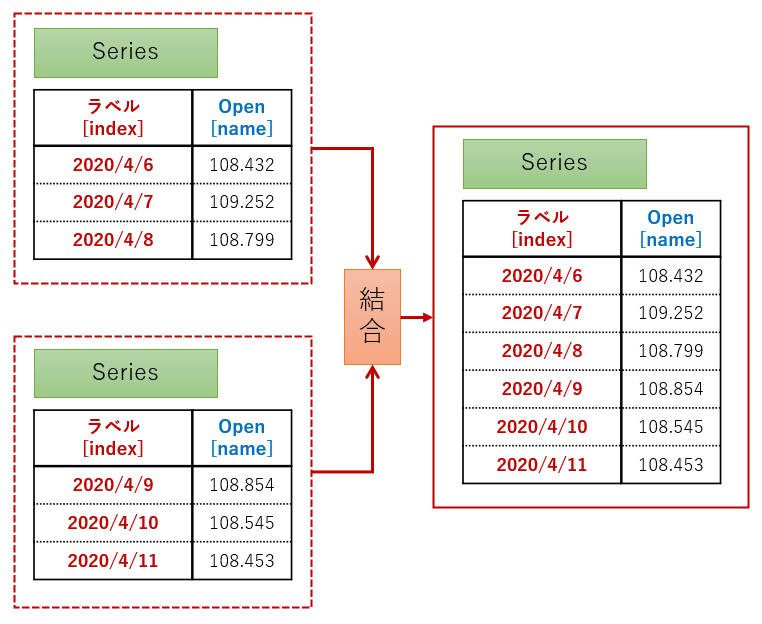
import pandas as pd
o_data1 = [108.432, 109.252, 108.799]
o_data2 = [108.854, 108.545, 108.453]
o_index1 = ["2020/4/6", "2020/4/7", "2020/4/8"]
o_index2 = ["2020/4/9", "2020/4/10", "2020/4/11"]
# Series1の生成
sr1 = pd.Series(data=o_data1, index=o_index1, name="open")
print(sr1)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
Name: open, dtype: float64
"""
# Series2の生成
sr2 = pd.Series(data=o_data2, index=o_index2, name="open")
print(sr2)
"""
2020/4/9 108.854
2020/4/10 108.545
2020/4/11 108.453
Name: open, dtype: float64
"""
# Series1とSeries2を結合
sr_c = pd.concat([sr1, sr2])
print(sr_c)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545
2020/4/11 108.453
Name: open, dtype: float64
"""
# 結合前のデータ(Series1とSeries2)は変更されていないことを確認
print(sr1)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
Name: open, dtype: float64
"""
print(sr2)
"""
2020/4/9 108.854
2020/4/10 108.545
2020/4/11 108.453
Name: open, dtype: float64
"""値の「削除」
Seriesから値を削除するにはdrop()を使用します。
使用方法は削除したい値のラベルを引数に指定するだけです。
1つだけの値を削除したい場合は単一のラベル名を、複数の値を削除したい場合はラベル名をリストで指定します。
削除後のデータは返り値で返され、元データは変更されません。
説明するにあたり、次のSeriesから値を削除する例をサンプルコードを使って説明してきます。
import pandas as pd
o_data = [108.432, 109.252, 108.799,
108.854, 108.545]
o_index = ["2020/4/6", "2020/4/7", "2020/4/8",
"2020/4/9", "2020/4/10"]
# Seriesの生成
sr = pd.Series(data=o_data, index=o_index, name="open")
print(sr)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545
Name: open, dtype: float64
"""単一の値の削除
1つだけの値を削除する場合は引数に単一のラベル名を指定します。
以下はラベル「2020/4/7」の値を削除するサンプルコードです。
削除後に元データが変更されていないことも確認しています。
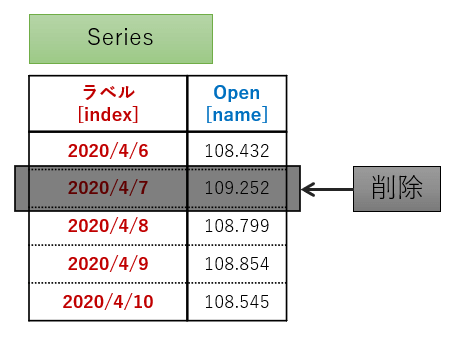
# 単一の値を削除
sr_d = sr.drop("2020/4/7")
print(sr_d)
"""
2020/4/6 108.432
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545
Name: open, dtype: float64
"""
# 元データは変更されていないことを確認
print(sr)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545
Name: open, dtype: float64
"""複数の値の削除(リスト指定)
複数の値を削除したい場合はラベル名をリストで指定します。
以下はラベル「2020/4/7」と「2020/4/9」の2つの値を削除するサンプルコードです。
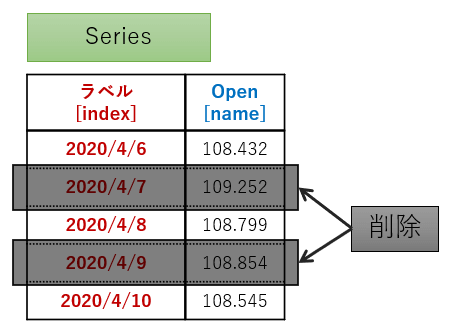
# 複数の値を削除
sr_d = sr.drop(["2020/4/7", "2020/4/9"])
print(sr_d)
"""
2020/4/6 108.432
2020/4/8 108.799
2020/4/10 108.545
Name: open, dtype: float64
"""【One Up】これも知っておこう!
drop()にはオプションでいくつか引数が用意されていますが、その中でも下表の2つは個人的に使用頻度が高く、知っておいて損はありませんのでこのタイミングで使い方を覚えてしまいましょう!
| 引数パラメータ | デフォルト設定値 | 説明 |
|---|---|---|
inplace | False | Trueの場合、元データを変更し、返り値はNoneとなる。 |
errors | ‘raise’ | ‘ignore’or‘raise’が指定可能。‘raise’の場合、存在しないラベルが指定されるとKeyErrorが発生するが、‘ignore’の場合だとエラーが発生しなくなる。 |
inplace = True
inplace = Trueとすると元データが変更されます。
元データが変更されるので、返り値が返されなくなります。
基本的にSeriesから値を削除する場合、元データを変更したい場合がほとんどだと思いますので使用頻度はかなり高いです。
# 元データの中身を確認
print(sr)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545
Name: open, dtype: float64
"""
# 値を削除し、元データを変更する(inplace=True)
sr.drop(["2020/4/7", "2020/4/9"], inplace=True)
# 元データの中身を確認
print(sr)
"""
2020/4/6 108.432
2020/4/8 108.799
2020/4/10 108.545
Name: open, dtype: float64
"""errors = “ignore”
通常、指定したラベルがSeries内に存在しなかった場合は、KeyErrorが発生しますが、引数errors="ignore"を指定するとKeyErrorが発生しなくなり、元データと同じデータが返り値で返されます。
「指定したラベルが存在したときは削除するが、存在しなかった場合は何もしない」といった挙動にしたい場合はerrors="ignore"を指定すると良いでしょう!
# 元データの中身を確認
print(sr)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545
Name: open, dtype: float64
"""
# 存在しないラベルを指定するとKeyError発生
try:
# 存在しないラベル"aaa"を指定する
sr_d = sr.drop("aaa")
except KeyError as err:
print(err)
"""
KeyError: "['aaa'] not found in axis"
"""
# errors="ignore"を指定するとKeyErrorが発生しなくなる
sr_d = sr.drop("aaa", errors="ignore")
print(sr_d)
"""
2020/4/6 108.432
2020/4/7 109.252
2020/4/8 108.799
2020/4/9 108.854
2020/4/10 108.545
Name: open, dtype: float64
"""参考


{kind=link}
コメント