
こんにちは、たっきん(Twitter)です!
ここでは、DataFrameの作成と基本構造について説明していきます。
Pandasを使用する場合、ほぼ間違いなく使用することになるのがこの「DataFrame」になります。
ここではDataFrameの基本構造について、要点をなるべくシンプルに纏めましたので基礎知識としてしっかり身に着けていきましょう!
Pandas記事全容(目次)になります。
Pandasについて、他に困りごとある場合はこちらで答えが見つかるかもしれませんので、よかったら参考にしてみてください。


DataFrameの基本構造
DataFrameの基本構造は2次元のテーブルデータとなります。
NumPyなどの二次元配列のテーブルデータとは異なり、DataFrameは行と列にラベル(見出し)を設定することができます。
このラベルを指定することで任意の行・列に対し、データ抽出や様々な演算を行うことができることがDataFrameの最大の特徴です。
下表のような日足のOHLC(ローソク足)データを例にして説明すると、datetime(日付)が行ラベル、「Open, High, Low, Close」が列ラベルとなります。
- 行ラベル → datetime (2020/4/1~2020/4/4)
- 列ラベル → Open, High, Low, Close
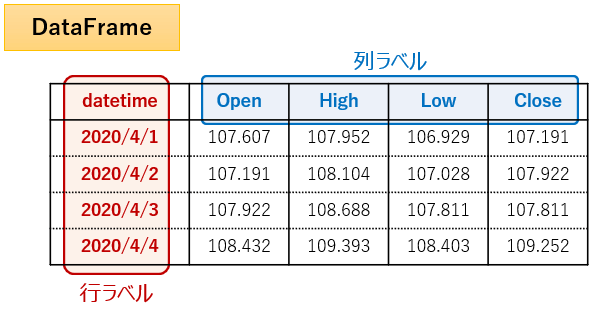
以下は日足のOHLC(ローソク足)データをDataFrame型で作成し、datetime列を行ラベルとして設定するコードになります。
import pandas as pd
ohlc_data = [
["2020/4/6", 108.432, 109.393, 108.403, 109.252],
["2020/4/7", 109.252, 109.294, 108.680, 108.799],
["2020/4/8", 108.799, 109.109, 108.514, 108.854],
["2020/4/9", 108.854, 109.071, 108.218, 108.545],
["2020/4/10", 108.545, 108.615, 108.341, 108.515]
]
# OHLC(ローソク足)のDataFrameを作成
df_ohlc = pd.DataFrame(ohlc_data,
columns=["datetime", "ask_o", "ask_h", "ask_l", "ask_c"])
print(df_ohlc)
"""
datetime open high low close
0 2020/4/6 108.432 109.393 108.403 109.252
1 2020/4/7 109.252 109.294 108.680 108.799
2 2020/4/8 108.799 109.109 108.514 108.854
3 2020/4/9 108.854 109.071 108.218 108.545
4 2020/4/10 108.545 108.615 108.341 108.515
"""
# datetime列をインデックスに設定
df_ohlc.set_index("datetime", inplace=True)
print(df_ohlc)
"""
open high low close
datetime
2020/4/6 108.432 109.393 108.403 109.252
2020/4/7 109.252 109.294 108.680 108.799
2020/4/8 108.799 109.109 108.514 108.854
2020/4/9 108.854 109.071 108.218 108.545
2020/4/10 108.545 108.615 108.341 108.515
"""
行・列ラベルの取得
DataFrameでは、行・列ラベルには下記の属性が割り当てられています。
- 行ラベル →
index - 列ラベル →
columns
行ラベルと列ラベルはそれぞれ、index、columnsで取得することができますが、Index型として取得されてしまいます。
to_list()でlist型として取得できます。
list型の方が扱いやすいため、基本的にto_list()で取得したほうが良いです。
# インデックス(行ラベル)の取得
print(df_ohlc.index)
"""
Index(['2020/4/6', '2020/4/7', '2020/4/8', '2020/4/9', '2020/4/10'],
dtype='object', name='datetime')
"""
# 型の確認
print(type(df_ohlc.index))
"""
<class 'pandas.core.indexes.base.Index'>
"""
# インデックス(行ラベル)をlist型で取得
index_list = df_ohlc.index.to_list()
print(index_list)
"""
['open', 'high', 'low', 'close']
"""
# 型の確認
print(type(index_list))
"""
<class 'list'>
"""# カラム(列ラベル)の取得
print(df_ohlc.columns)
"""
Index(['open', 'high', 'low', 'close'], dtype='object')
"""
# 型の確認
print(type(df_ohlc.columns))
"""
<class 'pandas.core.indexes.base.Index'>
"""
# カラム(列ラベル)をlist型で取得
columns_list = df_ohlc.columns.to_list()
print(columns_list)
"""
['open', 'high', 'low', 'close']
"""
# 型の確認
print(type(columns_list))
"""
<class 'list'>
"""DataFrameとSeriesの相互関係
DataFrameを扱う上でもう1つ、重要なデータ型があります。
Seriesというデータ構造です。
DataFrameがラベル付きの2次元のデータ構造であったのに対し、Seriesはラベル付き1次元のデータ構造になります。
そのため、DataFrameから任意の1列、または1行を抽出した場合、抽出されたデータはSeries型として取得されます。
DataFrameから1列を抽出 (DataFrame → Series)
DataFrameから任意の1列を抽出した場合、Seriesは下図のようなデータ構造となります。
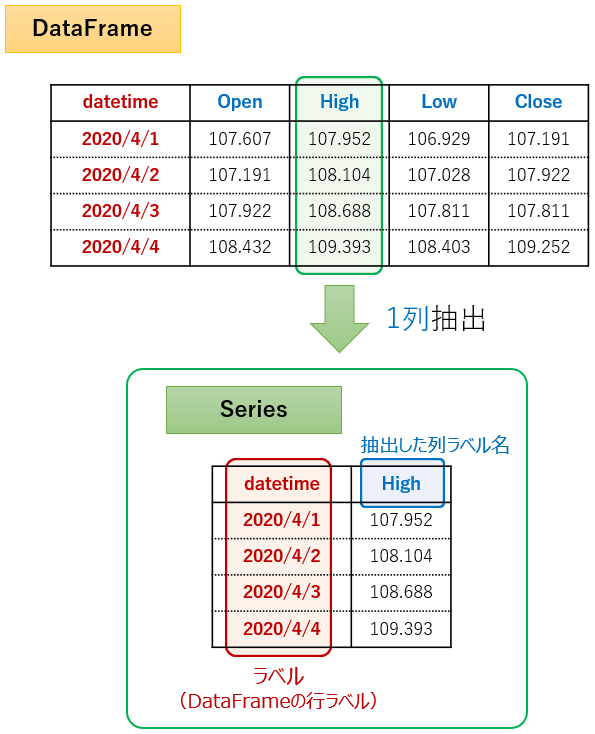
Series型として取得された後のラベル(DataFrameの行ラベル)、抽出した列ラベル名は下記の属性で取得できます。
- ラベル(DataDrameの行ラベル) →
index - 抽出した列ラベル名 →
name
例としてDataFrame型のOHLC(ローソク足)データから、任意の1列「high」を抽出するコードで動作を確認してみましょう。
# DataFrame(df_ohlc)の中身を確認
print(df_ohlc)
"""
open high low close
datetime
2020/4/6 108.432 109.393 108.403 109.252
2020/4/7 109.252 109.294 108.680 108.799
2020/4/8 108.799 109.109 108.514 108.854
2020/4/9 108.854 109.071 108.218 108.545
2020/4/10 108.545 108.615 108.341 108.515
"""
# DataFrame(df_ohlc)から"high"列を抽出
sr_col = df_ohlc["high"]
print(sr_col)
"""
datetime
2020/4/6 109.393
2020/4/7 109.294
2020/4/8 109.109
2020/4/9 109.071
2020/4/10 108.615
Name: high, dtype: float64
"""
# 型の確認
print(type(sr_col))
"""
<class 'pandas.core.series.Series'>
"""
# ラベル(行ラベル)の取得
print(sr_col.index.to_list())
"""
['2020/4/6', '2020/4/7', '2020/4/8', '2020/4/9', '2020/4/10']
"""
# 抽出した列ラベル名の取得
print(sr_col.name)
"""
high
"""DataFrameから1行を抽出 (DataFrame → Series)
DataFrameから任意の1行を抽出した場合、Seriesは下図のようなデータ構造となります。
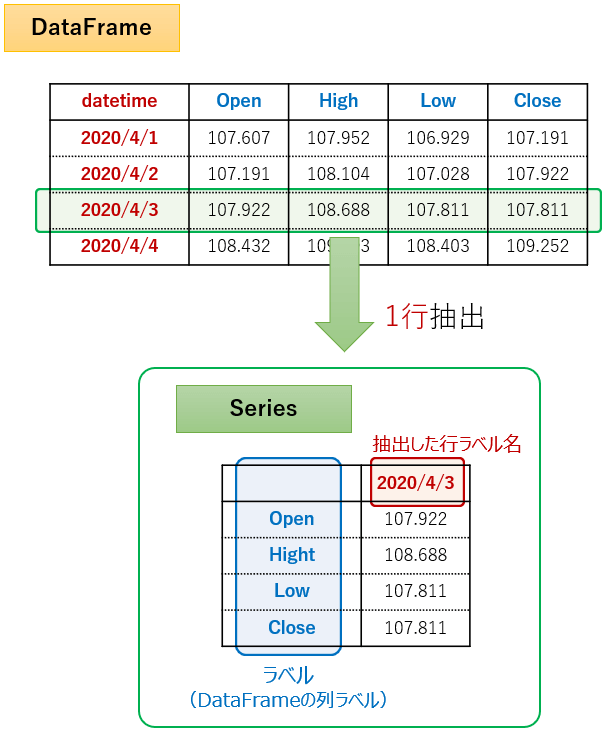
この場合、indexにはDataDrameの列ラベルが、nameには抽出した行ラベル名がそれぞれ設定されます。
- ラベル(DataDrameの列ラベル) →
index - 抽出した行ラベル名 →
name
例としてDataFrame型のOHLC(ローソク足)データから、任意の1行「2020/4/8」を抽出するコードで動作を確認してみましょう。
# DataFrame(df_ohlc)の中身を確認
print(df_ohlc)
"""
open high low close
datetime
2020/4/6 108.432 109.393 108.403 109.252
2020/4/7 109.252 109.294 108.680 108.799
2020/4/8 108.799 109.109 108.514 108.854
2020/4/9 108.854 109.071 108.218 108.545
2020/4/10 108.545 108.615 108.341 108.515
"""
# DataFrame(df_ohlc)から"2020/4/8"行を抽出
sr_row = df_ohlc.loc["2020/4/8"]
print(sr_row)
"""
open 108.799
high 109.109
low 108.514
close 108.854
Name: 2020/4/8, dtype: float64
"""
# 型の確認
print(type(sr_row))
"""
<class 'pandas.core.series.Series'>
"""
# ラベル(列ラベル)の取得
print(sr_row.index.to_list())
"""
['open', 'high', 'low', 'close']
"""
# 抽出した行ラベル名の取得
print(sr_col.name)
"""
2020/4/8
"""

コメント