
たっきん(Twitter)です!
今回は、DataFrameの行・列の削除方法について説明していきます。
行・列の削除はそれほど難しくなく、基本的にdrop()メソッド(関数)を使うだけです。
引数の指定も比較的シンプルなので、さくっと学習していきましょう!
drop()で行列を削除する場合、削除する方向(行・列)は引数で指定します。
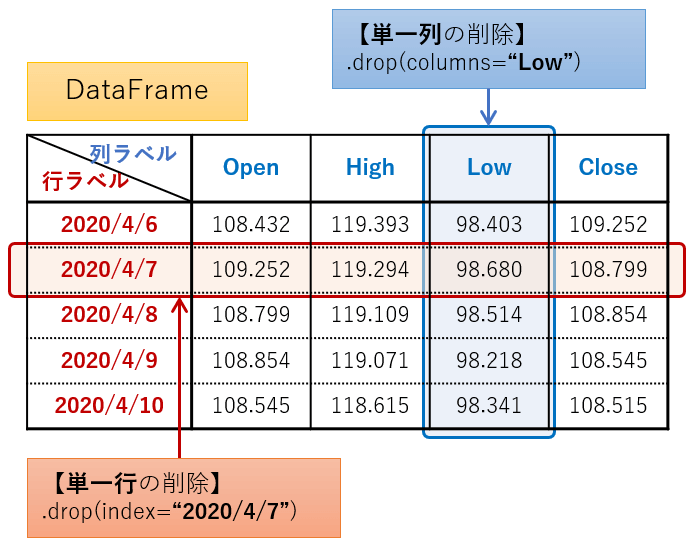
行を削除する場合は引数indexに、列を削除する場合は引数columnsに、それぞれ削除したい行・列をラベル名で指定します。
| 削除する方向 | 引数の指定 |
|---|---|
| 行 | .drop(index="行ラベル") |
| 列 | .drop(columns="列ラベル") |
drop()のAPI referenceを見ると、引数labelsとaxisでも削除する行・列を指定できますが正直、この2つの引数は使用しなくてよいです。
同じことが引数index、columnsでできるのと、こちらを使用する方がシンプルでわかりやすいからです。
全てのAPIに言えますが、全てを理解する必要はありません。
知識は必要最小限に留めておきましょう!
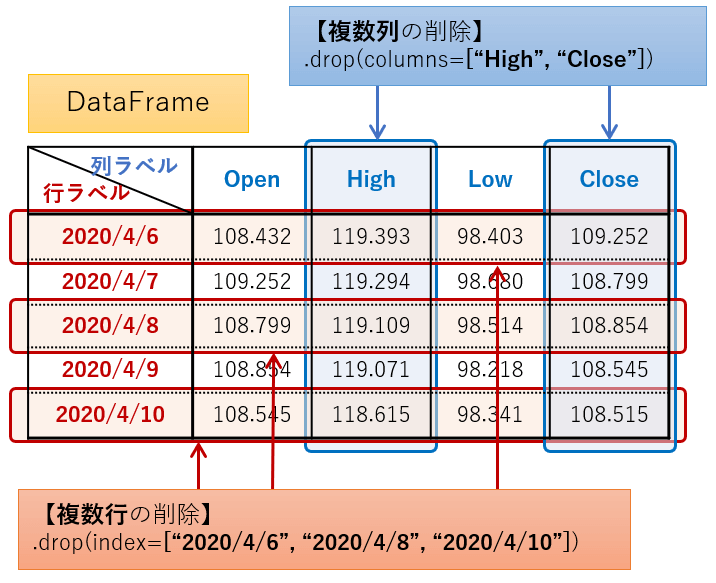
引数indexとcolumnsのラベル名の指定方法ですが、単一行・列を削除したい場合は、単一ラベル名を、複数行をまとめて削除したい場合はリストで指定します。
【単一行・列の削除】(単一ラベル名で指定)
【複数行・列の削除】(リストで指定)
また、drop()メソッドは削除後のデータを返り値で返します。
このとき、元データは変更されません。
元データを変更したい場合は引数にinplace=Trueを指定します。
Pandas記事全容(目次)になります。
Pandasについて、他に困りごとある場合はこちらで答えが見つかるかもしれませんので、よかったら参考にしてみてください。


行の削除
単一行の削除、複数行をまとめて削除するサンプルコードで動作を確認してみましょう!
import pandas as pd
ohlc_data = [
["2020/4/6", 108.432, 119.393, 98.403, 109.252],
["2020/4/7", 109.252, 119.294, 98.680, 108.799],
["2020/4/8", 108.799, 119.109, 98.514, 108.854],
["2020/4/9", 108.854, 119.071, 98.218, 108.545],
["2020/4/10", 108.545, 118.615, 98.341, 108.515],
]
df = pd.DataFrame(ohlc_data, columns=["datetime", "open", "high", "low", "close"])
df.set_index("datetime", inplace=True)
print(df)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/7 109.252 119.294 98.680 108.799
2020/4/8 108.799 119.109 98.514 108.854
2020/4/9 108.854 119.071 98.218 108.545
2020/4/10 108.545 118.615 98.341 108.515
"""
# 単一行の削除
df_s = df.drop(index="2020/4/8")
print(df_s)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/7 109.252 119.294 98.680 108.799
2020/4/9 108.854 119.071 98.218 108.545
2020/4/10 108.545 118.615 98.341 108.515
"""
# 元データが変更されていないことを確認
print(df)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/7 109.252 119.294 98.680 108.799
2020/4/8 108.799 119.109 98.514 108.854
2020/4/9 108.854 119.071 98.218 108.545
2020/4/10 108.545 118.615 98.341 108.515
"""
# 複数行の削除
df_l = df.drop(index=["2020/4/7", "2020/4/9"])
print(df_l)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/8 108.799 119.109 98.514 108.854
2020/4/10 108.545 118.615 98.341 108.515
"""
# 元データを変更(inplace=True)
df.drop(index=["2020/4/7", "2020/4/9"], inplace=True)
print(df)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/8 108.799 119.109 98.514 108.854
2020/4/10 108.545 118.615 98.341 108.515
"""列の削除
単一列の削除、複数列をまとめて削除するサンプルコードで動作を確認してみましょう!
import pandas as pd
ohlc_data = [
["2020/4/6", 108.432, 119.393, 98.403, 109.252],
["2020/4/7", 109.252, 119.294, 98.680, 108.799],
["2020/4/8", 108.799, 119.109, 98.514, 108.854],
["2020/4/9", 108.854, 119.071, 98.218, 108.545],
["2020/4/10", 108.545, 118.615, 98.341, 108.515],
]
df = pd.DataFrame(ohlc_data, columns=["datetime", "open", "high", "low", "close"])
df.set_index("datetime", inplace=True)
print(df)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/7 109.252 119.294 98.680 108.799
2020/4/8 108.799 119.109 98.514 108.854
2020/4/9 108.854 119.071 98.218 108.545
2020/4/10 108.545 118.615 98.341 108.515
"""
# 単一列の削除
df_s = df.drop(columns="high")
print(df_s)
"""
open low close
datetime
2020/4/6 108.432 98.403 109.252
2020/4/7 109.252 98.680 108.799
2020/4/8 108.799 98.514 108.854
2020/4/9 108.854 98.218 108.545
2020/4/10 108.545 98.341 108.515
"""
# 元データが変更されていないことを確認
print(df)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/7 109.252 119.294 98.680 108.799
2020/4/8 108.799 119.109 98.514 108.854
2020/4/9 108.854 119.071 98.218 108.545
2020/4/10 108.545 118.615 98.341 108.515
"""
# 複数列の削除
df_l = df.drop(columns=["open", "low"])
print(df_l)
"""
high close
datetime
2020/4/6 119.393 109.252
2020/4/7 119.294 108.799
2020/4/8 119.109 108.854
2020/4/9 119.071 108.545
2020/4/10 118.615 108.515
"""
# 元データを変更(inplace=True)
df.drop(columns=["open", "low"], inplace=True)
print(df)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/8 108.799 119.109 98.514 108.854
2020/4/10 108.545 118.615 98.341 108.515
"""指定したラベルがDataFrame内に存在しない場合
通常、指定したラベルがDataFrame内に存在しなかった場合は、KeyErrorが発生しますが、引数errors="ignore"を指定するとKeyErrorが発生しなくなり、元データと同じデータが返り値で返されます。
「指定したラベルが存在したときは削除するが、存在しなかった場合は何もしない」といった挙動にしたい場合はerrors="ignore"を指定すると良いでしょう!
print(df)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/7 109.252 119.294 98.680 108.799
2020/4/8 108.799 119.109 98.514 108.854
2020/4/9 108.854 119.071 98.218 108.545
2020/4/10 108.545 118.615 98.341 108.515
"""
try:
# 存在しないカラム"aaa"を指定する
df_s = df.drop(columns="aaa")
except KeyError as err:
print(err)
"""
"['aaa'] not found in axis"
"""
# errors="ignore"を指定するとKeyErrorが発生しなくなる
df_s = df.drop(columns="aaa", errors="ignore")
print(df_s)
"""
open high low close
datetime
2020/4/6 108.432 119.393 98.403 109.252
2020/4/7 109.252 119.294 98.680 108.799
2020/4/8 108.799 119.109 98.514 108.854
2020/4/9 108.854 119.071 98.218 108.545
2020/4/10 108.545 118.615 98.341 108.515
"""参考


コメント