
たっきん(Twitter)です!
今回はマルチインデックスの操作方法について説明していきます。
今までの説明ではインデックスは1列しか設定してきませんでしたが、実はインデックスは複数列を指定して設定することができます。
複数列のインデックスをマルチインデックスといいます。
【通常のインデックス】
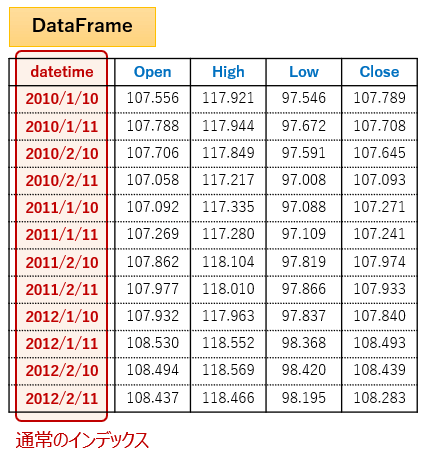
【マルチインデックス】
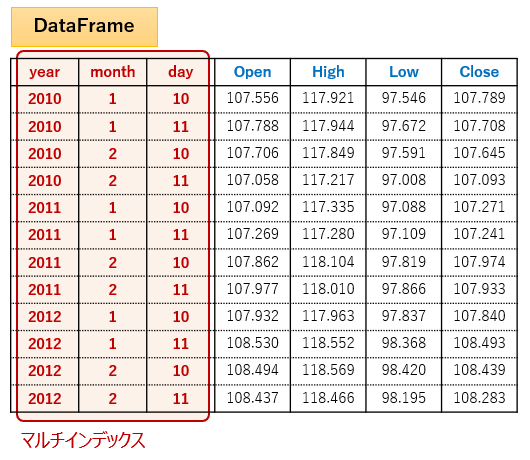
マルチインデックスを使用するメリットは通常インデックスよりも細かい条件を指定してデータにアクセスできることです。
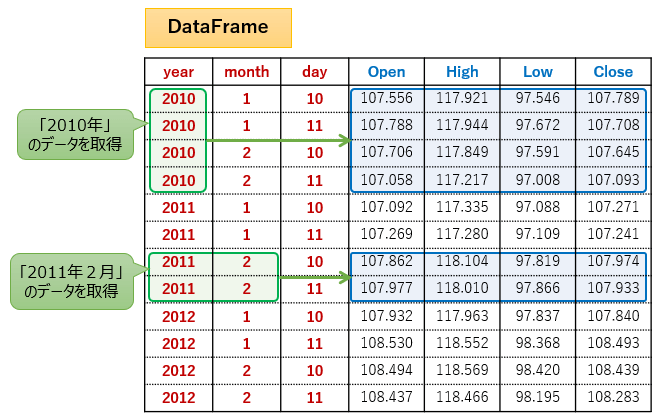
例えば上図のように、日付を「年(year)」,「 月(month)」,「 日(day)」の3つに分けてマルチインデックスを構成した場合、「2010年」の行データ、「2011年2月」の行データの取得などが容易に行えるようになります。
僕も実際にシストレ開発で大量の時系列OHLCデータを扱う際に、日付をマルチインデックスに設定してデータ処理していました。
マルチインデックスの扱い方も慣れないうちは混乱してしまうと思うので、要点だけを絞ってシンプルに説明していきます。
Pandas記事全容(目次)になります。
Pandasについて、他に困りごとある場合はこちらで答えが見つかるかもしれませんので、よかったら参考にしてみてください。


マルチインデックスの設定
マルチインデックスを設定するにはDataFrame.set_index()を使用します。
通常のインデックス指定もDataFrame.set_index()を使用しましたが、違いはインデックスに指定する列ラベルを単一で指定するか、リストで複数指定するかになります。
リストで列ラベルを複数指定するとマルチインデックスとなります。
import pandas as pd
ohlc_data = [
[2010, 1, 10, 107.556, 117.921, 97.546, 107.789],
[2010, 1, 11, 107.788, 117.944, 97.672, 107.708],
[2010, 2, 10, 107.706, 117.849, 97.591, 107.645],
[2010, 2, 11, 107.058, 117.217, 97.008, 107.093],
[2011, 1, 10, 107.092, 117.335, 97.088, 107.271],
[2011, 1, 11, 107.269, 117.280, 97.109, 107.241],
[2011, 2, 10, 107.862, 118.104, 97.819, 107.974],
[2011, 2, 11, 107.977, 118.010, 97.866, 107.933],
[2012, 1, 10, 107.932, 117.963, 97.837, 107.840],
[2012, 1, 11, 108.530, 118.552, 98.368, 108.493],
[2012, 2, 10, 108.494, 118.569, 98.420, 108.439],
[2012, 2, 11, 108.437, 118.466, 98.195, 108.283],
]
df = pd.DataFrame(
ohlc_data,
columns=["year", "month", "day", "open", "high", "low", "close"]
)
# 元データの中身を確認
print(df)
"""
year month day open high low close
0 2010 1 10 107.556 117.921 97.546 107.789
1 2010 1 11 107.788 117.944 97.672 107.708
2 2010 2 10 107.706 117.849 97.591 107.645
3 2010 2 11 107.058 117.217 97.008 107.093
4 2011 1 10 107.092 117.335 97.088 107.271
5 2011 1 11 107.269 117.280 97.109 107.241
6 2011 2 10 107.862 118.104 97.819 107.974
7 2011 2 11 107.977 118.010 97.866 107.933
8 2012 1 10 107.932 117.963 97.837 107.840
9 2012 1 11 108.530 118.552 98.368 108.493
10 2012 2 10 108.494 118.569 98.420 108.439
11 2012 2 11 108.437 118.466 98.195 108.283
"""
# インデックスに["year", "month", "day"]を設定
df_i = df.set_index(["year", "month", "day"])
# DataFrameの中身を確認
print(df_i)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 117.849 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""また、マルチインデックスをindex.to_list()で取得すると、(year, month, day)の行ラベルがタプルで取得されます。
# インデックスを確認
print(df_i.index.to_list())
"""
[
(2010, 1, 10), (2010, 1, 11), (2010, 2, 10),
(2010, 2, 11), (2011, 1, 10), (2011, 1, 11),
(2011, 2, 10), (2011, 2, 11), (2012, 1, 10),
(2012, 1, 11), (2012, 2, 10), (2012, 2, 11)
]
"""マルチインデックスの解除
マルチインデックスを解除するには通常のインデックスと同じく、DataFrame.reset_index()を使用します。
マルチインデックスが解除されると、元のインデックスが列データに追加され、新しく「0, 1, 2,・・・」のような連番がデフォルト・インデックスとして設定されます。
通常のインデックスの場合と動作は全く一緒ですね!
# 元データの中身を確認
print(df)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 117.849 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""
# インデックスを確認
print(df.index.to_list())
"""
[
(2010, 1, 10), (2010, 1, 11), (2010, 2, 10),
(2010, 2, 11), (2011, 1, 10), (2011, 1, 11),
(2011, 2, 10), (2011, 2, 11), (2012, 1, 10),
(2012, 1, 11), (2012, 2, 10), (2012, 2, 11)
]
"""
# マルチインデックスの解除
df_r = df.reset_index()
# 解除後のデータの中身を確認
print(df_r)
"""
year month day open high low close
0 2010 1 10 107.556 117.921 97.546 107.789
1 2010 1 11 107.788 117.944 97.672 107.708
2 2010 2 10 107.706 117.849 97.591 107.645
3 2010 2 11 107.058 117.217 97.008 107.093
4 2011 1 10 107.092 117.335 97.088 107.271
5 2011 1 11 107.269 117.280 97.109 107.241
6 2011 2 10 107.862 118.104 97.819 107.974
7 2011 2 11 107.977 118.010 97.866 107.933
8 2012 1 10 107.932 117.963 97.837 107.840
9 2012 1 11 108.530 118.552 98.368 108.493
10 2012 2 10 108.494 118.569 98.420 108.439
11 2012 2 11 108.437 118.466 98.195 108.283
"""
# インデックスを確認
print(df_r.index.to_list())
"""
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
"""指定データの取得・変更
指定された行ラベルの位置にあるデータを取得・変更するには2通りの方法があります。
.loc[]を使用する方法と.xs()を使用する方法です。
.loc[]と.xs()ではできること、できないことに違いがあり、用途に応じて使い分ける必要があります。
できること、できないことは次の表に簡単にまとめていますが、具体的な内容についてはサンプルコードを使って説明していきます。
| 比較項目 | .loc[] | .xs() |
|---|---|---|
| ①行データ取得 | △ | ○ |
| ②行列指定の要素データ取得 | ○ | × |
| ③データの変更 | ○ | × |
.loc[]を使用したデータの取得・変更
.loc[]を使用したデータ取得・変更方法は基本的に通常のインデックスと同じで、記述方法は次のようになります。
.loc["行ラベル", "列ラベル"]

マルチインデックスの場合だと「行ラベル」がタプルでの指定に変わります。
サンプルコードで操作を確認していきましょう!
①行データ取得
行データ取得は次のように記述します。
.loc["行ラベル"]
(または、.loc["行ラベル", :])
以下は「年(year)」,「 月(month)」,「 日(day)」のマルチインデックスで構成されたDataFrameから行データを取得するサンプルコードになります。
# 元データの中身を確認
print(df)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 117.849 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""「2011年」の行を全て取得したい場合は、.loc[2011](または.loc[2011, :])と指定します。
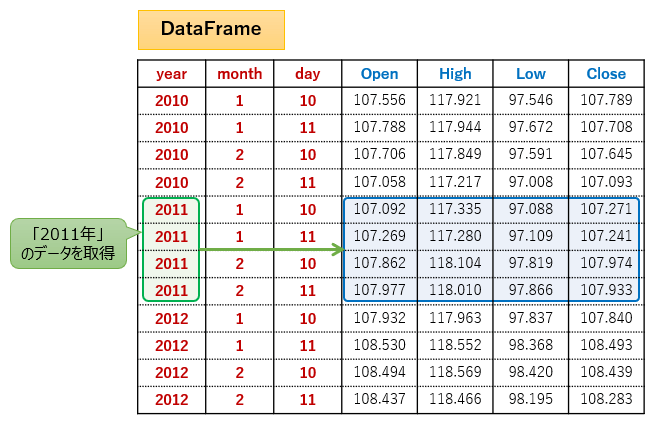
# 行データ取得
# year = 2011
df_r = df.loc[2011]
print(df_r)
"""
open high low close
month day
1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
"""「2011年2月」の行を全て取得したい場合は、.loc[(2011, 2)](または.loc[(2011, 2), :])のようにタプルで指定します。
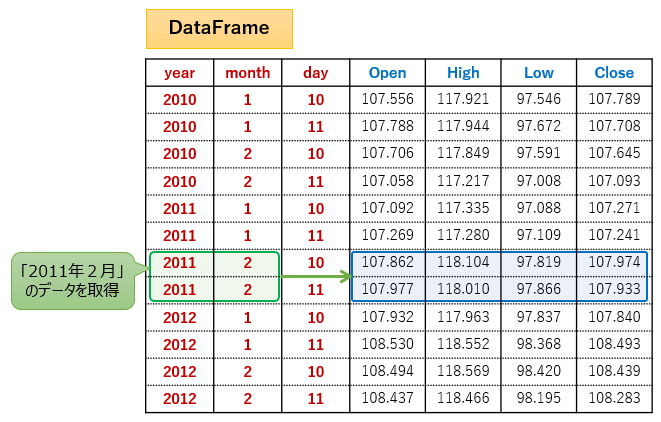
# 行データ取得
# year = 2011
# month = 2
df_r = df.loc[(2011, 2)]
print(df_r)
"""
open high low close
day
10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
"""「2011年2月10日」の行を取得したい場合は、.loc[(2011, 2, 10)](または.loc[(2011, 2, 10), :])のようにタプルで指定します。
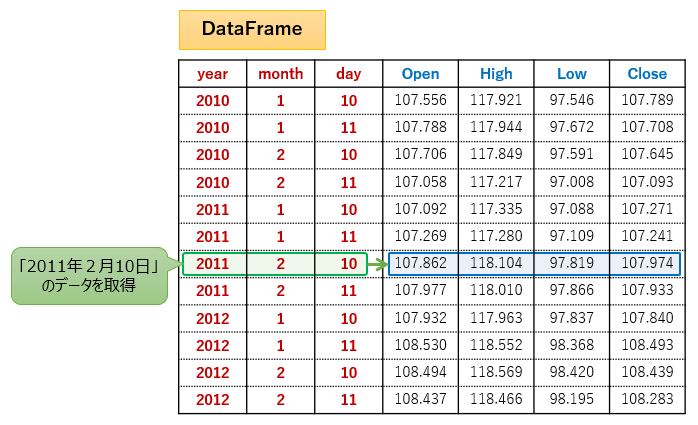
ここまで指定すると取得される行は1行のみとなるため、Series型で取得されます。
# 行データ取得
# year = 2011
# month = 2
# day = 10
sr_r = df.loc[(2011, 2, 10)]
print(sr_r)
"""
open 107.862
high 118.104
low 97.819
close 107.974
Name: (2011, 2, 10), dtype: float64
"""上記例のようにインデックスの指定を上位階層から順に指定する場合は問題なく取得できますが、階層を飛ばして指定(例えば、.loc[("month", "day")])することはできません。
これが、.loc[]を使用してデータ取得する場合の制約になります。
階層を飛ばして指定してデータを取得する場合は、.xs()を使用します。
| 指定の階層レベル | 指定可否 | 記述方法 |
|---|---|---|
| Lv.1 (year) | ○ | .loc["Lv.1", :] |
| Lv.1, 2 (year, month) | ○ | .loc[("Lv.1", "Lv.2"), :] |
| Lv.1, 2, 3 (year, month, day) | ○ | .loc[("Lv.1", "Lv.2", "Lv.3"), :] |
| Lv.2, 3 (month, day) | × | ※Lv.1(year)を飛ばしているため指定不可 |
| Lv.1, 3 (year, day) | × | ※Lv.2(month)を飛ばしているため指定不可 |
②行列指定の要素データ取得
行列指定の要素データ取得は次のように記述します。
.loc["行ラベル", "列ラベル"]
「2011年2月10日」の行と「High」の列の要素データを取得したい場合は、.loc[(2011, 2, 10), "high"]と指定します。
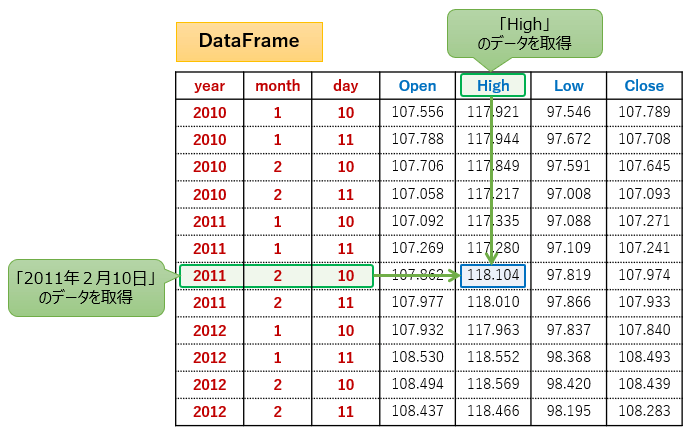
# 元データの中身を確認
print(df)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 117.849 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""
# 行指定の要素データ取得
elem = df.loc[(2011, 2, 10), "high"]
print(elem)
"""
118.104
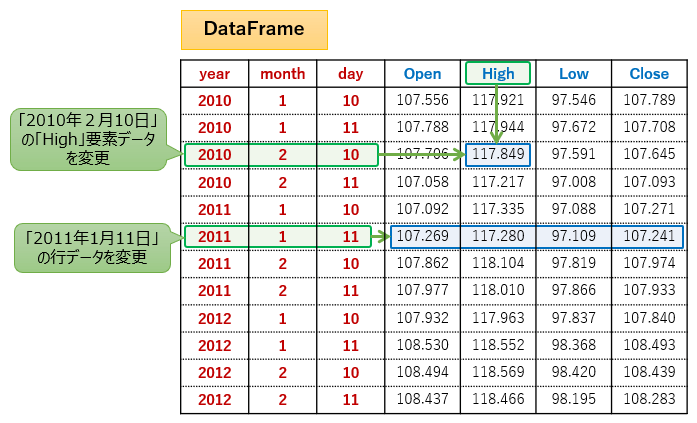
"""③データの変更
データの変更は次のように記述します。
.loc["行ラベル", "列ラベル"]= 変更したい値
単一要素のデータと1行データを変更するサンプルコードを用意したので動作を確認してみましょう!
# 元データの中身を確認
print(df)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 117.849 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""
# データの変更(単一要素のデータ)
df.loc[(2010, 2, 10), "high"] = 555.555
print(df)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 555.555 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""
# データの変更(1行のデータ)
df.loc[(2011, 1, 11), :] = [999.999, 999.999, 999.999, 999.999]
print(df)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 555.555 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 999.999 999.999 999.999 999.999
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
""".xs()を使用したデータの取得
.xs()は.loc[]と同じくマルチインデックスで構成されたDataFrameの行データが取得できますが、一番の違いはマルチインデックスの階層を指定して行データが取得できることです。
例えば、.loc[]で指定不可だった下記の階層レベルの行データ取得が.xs()だと可能になります。
| 指定の階層レベル | 指定可否 | 記述方法 |
|---|---|---|
| Lv.2, 3 (month, day) | × | ※Lv.1を飛ばしているため指定不可 |
| Lv.1, 3 (year, day) | × | ※Lv.2を飛ばしているため指定不可 |
①行データ取得
行データ取得は次のように記述します。
.xs(key="マルチインデックス内のラベル", level="keyで指定したラベルの階層")
※”key=”は第1引数のため省略可能
keyとlebelは複数指定することができ、その場合はタプルで記述します。
「年(year)」,「 月(month)」,「 日(day)」のマルチインデックスで構成されたDataFrameから行データを取得するサンプルコードで動作を確認していきましょう!
# 元データの中身を確認
print(df)
"""
open high low close
year month day
2010 1 10 107.556 117.921 97.546 107.789
11 107.788 117.944 97.672 107.708
2 10 107.706 117.849 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 1 10 107.092 117.335 97.088 107.271
11 107.269 117.280 97.109 107.241
2 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 1 10 107.932 117.963 97.837 107.840
11 108.530 118.552 98.368 108.493
2 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""「2月」の行を取得したい場合は、.xs(2, level="month")と指定します。
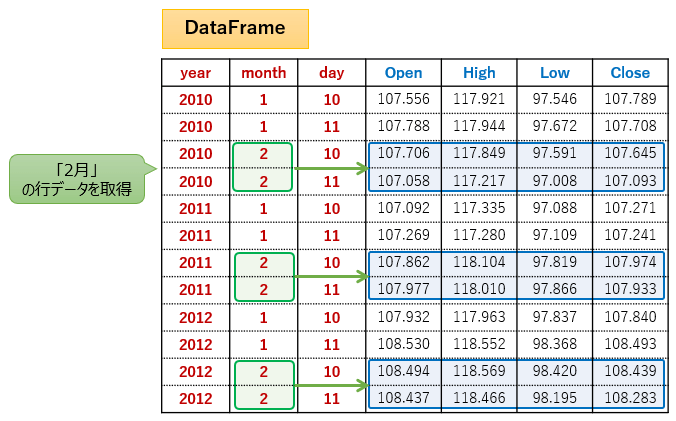
# 行データ取得
# month= 2
df_r = df.xs(2, level="month")
print(df_r)
"""
open high low close
year day
2010 10 107.706 117.849 97.591 107.645
11 107.058 117.217 97.008 107.093
2011 10 107.862 118.104 97.819 107.974
11 107.977 118.010 97.866 107.933
2012 10 108.494 118.569 98.420 108.439
11 108.437 118.466 98.195 108.283
"""「2011年10日」の行を取得したい場合は、.xs((2011, 10), level=("year", "day"))のようにタプルで指定します。
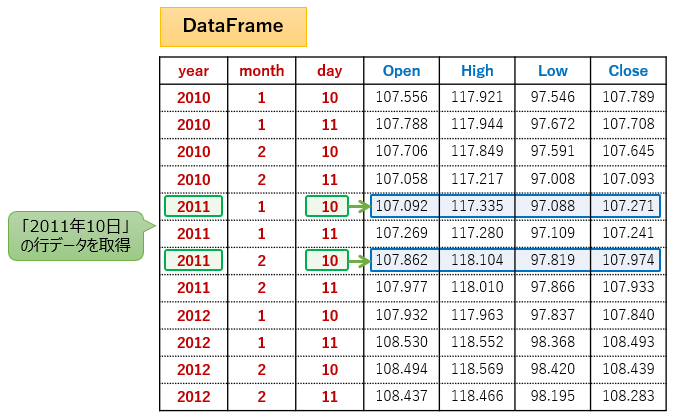
# 行データ取得
# year = 2011
# day = 2
df_r = df.xs((2011, 10), level=("year", "day"))
print(df_r)
"""
open high low close
month
1 107.092 117.335 97.088 107.271
2 107.862 118.104 97.819 107.974
"""②行列指定の要素データ取得
※.xs()は行列指定の要素データ取得不可です。
③データの変更
※.xs()はデータ変更不可です。
マルチインデックスの並び替え(ソート)
マルチインデックスのソートする場合はsort_index()を使用します。
基本的な使い方は下記の記事で解説していますが、マルチインデックスの場合は引数levelで階層レベルを指定してソートすることができます。
.sort_index(level="階層レベルのラベル")

次の「年(year)」,「 月(month)」,「 日(day)」が順不同のマルチインデックスに対し、昇順にソートするサンプルコードを見ていきましょう!
# 順不同のマルチインデックスDataFrameの生成
ohlc_data = [
[2010, 5, 15, 107.058, 117.217, 97.008, 107.093],
[2011, 2, 13, 107.977, 118.010, 97.866, 107.933],
[2012, 4, 11, 108.437, 118.466, 98.195, 108.283],
[2010, 1, 18, 107.706, 117.849, 97.591, 107.645],
[2011, 6, 20, 107.862, 118.104, 97.819, 107.974],
[2012, 3, 22, 108.494, 118.569, 98.420, 108.439],
[2010, 5, 12, 107.788, 117.944, 97.672, 107.708],
[2011, 2, 16, 107.269, 117.280, 97.109, 107.241],
[2012, 4, 19, 108.530, 118.552, 98.368, 108.493],
[2010, 1, 21, 107.556, 117.921, 97.546, 107.789],
[2011, 6, 14, 107.092, 117.335, 97.088, 107.271],
[2012, 3, 17, 107.932, 117.963, 97.837, 107.840],
]
df = pd.DataFrame(
ohlc_data,
columns=["year", "month", "day", "open", "high", "low", "close"]
)
df.set_index(["year", "month", "day"], inplace=True)
print(df)
"""
open high low close
year month day
2010 5 15 107.058 117.217 97.008 107.093
2011 2 13 107.977 118.010 97.866 107.933
2012 4 11 108.437 118.466 98.195 108.283
2010 1 18 107.706 117.849 97.591 107.645
2011 6 20 107.862 118.104 97.819 107.974
2012 3 22 108.494 118.569 98.420 108.439
2010 5 12 107.788 117.944 97.672 107.708
2011 2 16 107.269 117.280 97.109 107.241
2012 4 19 108.530 118.552 98.368 108.493
2010 1 21 107.556 117.921 97.546 107.789
2011 6 14 107.092 117.335 97.088 107.271
2012 3 17 107.932 117.963 97.837 107.840
"""引数levelを指定しなかった場合は「年(year)」,「 月(month)」,「 日(day)」全てのラベルが昇順にソートされます。
ソートの優先順位は階層レベルが高い順になります。
今回の例だと「year」が一番高く、「day」が一番低くなります。
# マルチインデックス並び替え
df_s = df.sort_index()
print(df_s)
"""
<ソート優先度>
高 低
↓ ↓
open high low close
year month day
2010 1 18 107.706 117.849 97.591 107.645
21 107.556 117.921 97.546 107.789
5 12 107.788 117.944 97.672 107.708
15 107.058 117.217 97.008 107.093
2011 2 13 107.977 118.010 97.866 107.933
16 107.269 117.280 97.109 107.241
6 14 107.092 117.335 97.088 107.271
20 107.862 118.104 97.819 107.974
2012 3 17 107.932 117.963 97.837 107.840
22 108.494 118.569 98.420 108.439
4 11 108.437 118.466 98.195 108.283
19 108.530 118.552 98.368 108.493
"""階層レベルを指定してソートしたい場合は引数levelで指定します。
# マルチインデックス並び替え(「day」ラベル指定)
df_s = df.sort_index(level="day")
print(df_s)
"""
「day」でソート
↓
open high low close
year month day
2012 4 11 108.437 118.466 98.195 108.283
2010 5 12 107.788 117.944 97.672 107.708
2011 2 13 107.977 118.010 97.866 107.933
6 14 107.092 117.335 97.088 107.271
2010 5 15 107.058 117.217 97.008 107.093
2011 2 16 107.269 117.280 97.109 107.241
2012 3 17 107.932 117.963 97.837 107.840
2010 1 18 107.706 117.849 97.591 107.645
2012 4 19 108.530 118.552 98.368 108.493
2011 6 20 107.862 118.104 97.819 107.974
2010 1 21 107.556 117.921 97.546 107.789
2012 3 22 108.494 118.569 98.420 108.439
"""階層レベルを複数指定してソートしたい場合は引数levelにタプルで指定します。
この場合もソートの優先順位は階層レベルが高い順になります。
# マルチインデックス並び替え(「month」と「day」ラベル指定)
df_s = df.sort_index(level=("month", "day"))
print(df_s)
"""
「month」「day」でソート
↓ ↓
open high low close
year month day
2010 1 18 107.706 117.849 97.591 107.645
21 107.556 117.921 97.546 107.789
2011 2 13 107.977 118.010 97.866 107.933
16 107.269 117.280 97.109 107.241
2012 3 17 107.932 117.963 97.837 107.840
22 108.494 118.569 98.420 108.439
4 11 108.437 118.466 98.195 108.283
19 108.530 118.552 98.368 108.493
2010 5 12 107.788 117.944 97.672 107.708
15 107.058 117.217 97.008 107.093
2011 6 14 107.092 117.335 97.088 107.271
20 107.862 118.104 97.819 107.974
"""参考
- 【API reference】pandas.DataFrame.set_index
- 【API reference】pandas.DataFrame.reset_index
- 【API reference】pandas.DataFrame.xs
- 【API reference】pandas.DataFrame.sort_index
- 【User Guide】Sorting a MultiIndex


コメント